El ciclo for es una estructura cíclica cuya finalidad es ejecutar un código una cierta cantidad de veces. De manera general, en Python, la sintaxis de for es:
forkiniterable:# hacer algo
Donde iterable es justamente eso, un iterable de Python que puede ser desde una lista hasta un string. Para la i-ésima iteración la variable de ciclo k adoptará el valor en la i-ésima posición de iterable.
En ocasiones tenemos iterables dentro de otro iterable. Es posible acceder a cada elemento del sub-iterable utilizando múltiple variables de ciclo. Por ejemplo:
Una utilidad muy común es la de la función enumerate:
In [24]:
notas=[10,8,10,9,10,7]fork,notainenumerate(notas):print("La nota en posición {0} es: {1}".format(k,nota))
La nota en posición 0 es: 10
La nota en posición 1 es: 8
La nota en posición 2 es: 10
La nota en posición 3 es: 9
La nota en posición 4 es: 10
La nota en posición 5 es: 7
De manera muy breve, la variable de ciclo k devuelve la posición del elemento para cada iteración.
Las gráficas de barras nos sirven para representar porcentajes y proporciones. En Python podemos utilizar la librería Matplotlib para desarrollar este tipo de gráficas.
Matplotlib dispone de la función pie, cuya sintaxis depende del grado de personalización y control que se requiera sobre la gráfica de pastel a dibujar.
Para ejemplificar el uso de esta función vamos a suponer que se tienen los siguientes datos sobre algunas personas que tienen cierta cantidad de manzanas en su poder:
Nombre
Manzanas
Ana
20
Juan
10
Diana
25
Catalina
30
Para representar el porcentaje del total del cual dispone cada uno, podemos trazar una gráfica de pastel. Para ello realizamos lo siguiente:
Observe que lo primero que hacemos es importar la librería matplotlib, enseguida, en utilizando listas definimos los nombres y el número de manzanas correspondientes. Luego, la función pie acepta un primer argumento que contiene los valores absolutos de cada ítem, además, de un keyword argumentlabels que contiene las etiquetas correspondientes.
El aspecto achatado de la gráfica se puede solucionar utilizando la función axis.
Los colores también se pueden determinar y autocalcular utilizando un mapa de color específico. Enseguida se muestra un ejemplo donde la variación es sobre colores en tonos azules.
Es posible también segmentar o separar del bloque una o más de las rebanadas de la gráfica de pastel. Para ello se debe pasar una lista o tupla con valores entre 0 y n que indican el desfase respecto al centro, 0 indica ningún desfase y n un desfase equivalente a n*r, donde r es el radio de la gráfica de pastel.
En lo siguiente se extraen algunos datos correspondientes a los investigadores que pertenecen al SNI.
In [16]:
importwarningswarnings.filterwarnings("ignore",'This pattern has match groups')importpandasaspdimportmatplotlib.pyplotaspltimportmatplotlibasmplplt.style.use("ggplot")mpl.rcParams['xtick.labelsize']=6mpl.rcParams['ytick.labelsize']=6%matplotlib inline
# Datos tomados de: http://datosabiertos.conacyt.gob.mx/publico/default.aspxfilename="data/inv_sni.csv"data=pd.read_csv(filename,encoding="latin1")# leyendo datosdata.drop(data.columns[range(8,17)],axis=1,inplace=True)# Limpiando datos
ninv=sum(estados.values)# No. total de investigadoresprc_df=estados.to_frame("INVESTIGADORES")prc_df["Porcentaje"]=100*prc_df['INVESTIGADORES']/ninvprc_df
Sobre las instituciones del Tecnológico Nacional de México (TECNM)¶
Lo subsiguiente presenta el porcentaje de representación de las instituciones correspondientes al Tecnológico Nacional de México: es decir, todos los institutos tecnológicos centralizados y descentralizados, más el CENIDET y CIIDET.
In [24]:
TECNOLOGICOS=sum(inst[inst.index.str.contains("INSTITUTO TECNOLOGICO (SUP|DE)")])CENIDET=sum(inst[inst.index.str.contains("CENTRO NACIONAL DE INV*")])CIIDET=sum(inst[inst.index.str.contains("INTERDISCIPLINARIO [\w*\s*\.]* EDUCACION")])porcentaje_tecnm=100*(TECNOLOGICOS+CENIDET+CIIDET)/NUM_INVporcentaje_tecnm
Out[24]:
2.5347400926402472
Los 20 tecnológicos con mayor cantidad de investigadores son:
In [29]:
(inst[inst.index.str.contains("INSTITUTO TECNOLOGICO (SUP|DE)")][:20]).to_frame("No. de Investigadores")
En este pequeño post vamos a analizar (en realidad no, sólo a trazar grafiquitas con algunos datos de interés) datos del Consejo Nacional de Ciencia y Tecnología (CONACYT), que hasta hace unos días me listaba entre sus becarios nacionales. Pero bueno, ¿qué es el CONACYT?, según wikipedia:
El Consejo Nacional de Ciencia y Tecnología (Conacyt) es un organismo público descentralizado del gobierno federal mexicano dedicado a promover y estimular el desarrollo de la ciencia y la tecnología en ese país. Tiene la responsabilidad oficial para elaborar las políticas de ciencia y tecnología nacionales.
Por medio del Conacyt es posible para los estudiantes conseguir apoyo económico a fin de realizar estudios de posgrado (maestría o doctorado) en universidades con reconocida excelencia académica dentro y fuera del país.
En resumen el CONACYT posibilita que muchos de nosotros (jóvenes mexicanos) ingresemos a un programa de posgrado, mismo que debe pertenecer a un padrón de posgrados de calidad.
En lo subsiguiente vamos a tomar algunos datos públicos del CONACYT referentes a los becarios nacionales y trataremos de segmentar y/o clasificar la información obtenida, básicamente en lo que concierne
In [1]:
importpandasaspdimportmatplotlib.pyplotaspltimportmatplotlibasmplplt.style.use("ggplot")mpl.rcParams['xtick.labelsize']=6mpl.rcParams['ytick.labelsize']=6%matplotlib inline
# Datos tomados de: http://datosabiertos.conacyt.gob.mx/publico/default.aspxfilename="data/becas_nacionales.csv"data=pd.read_csv(filename)
acon=data['Area de Conocimiento'].value_counts()x=range(len(acon))plt.bar(x,acon.get_values(),0.3,align="center")plt.xticks(x,acon.keys(),rotation=90)plt.xlim(min(x)-0.5,max(x)+0.5);
Supongamos que en $x=x_1$ la derivada de la función $y=f(x)$ se reduce a cero, es decir, $f'(x)=0$. Admitamos, además que existe la segunda derivada, $f''(x)$, y es continua sobre cierta vecindad del punto $x_1$. Para este caso es válido el siguiente teorema:
Teorema 1. Si $f'(x_1)=0$, entonces en $x=x_1$ la función tiene máximo cuando $f''(x_1)<0$, y, un mínimo cuando $f''(x_1)>0$.
De acuerdo al teorema anterior, para caracterizar los puntos críticos de una función $f(x)$ es necesario utilizar el criterio de la segunda derivada. Entendiendo que los puntos críticos se obtiene de resolver la ecuación $f'(x)=0$.
En Python es posible realizar cálculo simbólico mediante la librería SymPy.
Ejemplo 1.Calcular y caracterizar los puntos críticos de la función $f(x) = x^3 - x$
Primero, y como siempre, importamos los módulos necesarios.
Para determinar si se trata de un mínimo o máximo, utilizamos el criterio de la segunda derivada, sustituyendo los puntos críticos en $f''(x)$, es decir:
In [51]:
d2f.subs(x,pc[0])# Primer punto crítico
Out[51]:
$$- 2 \sqrt{3}$$
In [52]:
d2f.subs(x,pc[1])# Segundo punto crítico
Out[52]:
$$2 \sqrt{3}$$
Con esto determinamos, acorde al teorema 1, que el primer punto crítico $\left(\frac{-\sqrt{3}}{3}\right)$ es un mínimo y el segundo $\left(\frac{\sqrt{3}}{3}\right)$ un máximo. Podemos comprobarlo trazando la gráfica correspondiente:
In [54]:
plot(f,(x,-1,1))
Out[54]:
<sympy.plotting.plot.Plot at 0x94ca890>
Podemos automatizar un poco este proceso definiendo una función que realice el procedimiento descrito.
In [84]:
defmaxminf(f):""" Calcula los máximos y mínimos de una función f(x) """df=diff(f,x)# 1era. derivadad2f=diff(f,x,2)# 2da. derivadapcs=solve(Eq(df,0))# puntos críticosforpinpcs:ifd2f.subs(x,p)>0:tipo="Min"elifd2f.subs(x,p)<0:tipo="Max"else:tipo="Indefinido"print("x = %f (%s)"%(p,tipo))
In [85]:
maxminf(x**3-x)
x = -0.577350 (Max)
x = 0.577350 (Min)
La función anterior puede arrojar errores cuando se tienen raíces complejas, lo cual podría considerarse mediante una estructura try-except o bien verificando si el punto crítico es un valor real.
En este blog ya hemos tratado algunas veces cómo desarrollar interfaces gráficas utilizando wxPython
(véase aquí). En este post vamos a presentar el
desarrollo de una mini-aplicación que calcula límites, derivadas e integrales utilizando SymPy como
motor de cálculo simbólico.
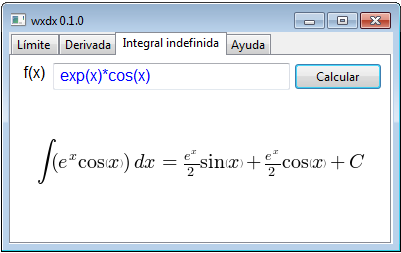
En la siguiente imagen se muestra la interfaz gráfica resultante:
Ahora vamos a describir un poco el diseño y funcionamiento de la aplicación. Como puede notarse
la aplicación está basada en la clase wxNotebook,
teniéndose cuatro páginas: Límites, Derivadas, Integrales indefinidas y Ayuda. Cada página del
Notebook contiene un instancia heredada de wxPanel, misma que contiene todos los controles
necesarios en cada uno de los casos.
El proceso de cálculo es básicamente como sigue: se lee una función $f(x)$ introducida en los
wxTextCtrl correspondientes y se hace un preprocesamiento mínimo, enseguida se transforma
el string leído en una expresión de SymPy, para luego llevar a cabo la operación
requerida. El resultado de la operación dado por SymPy se muestra en un canvas de Matplotlib,
en el cual se renderiza la expresión LaTeX del resultado obtenido.
El código de la aplicación completa se adjunta a continuación.
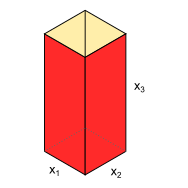
Ejemplo. Se requiere diseñar un contenedor de desechos, cuya forma será la de un prisma rectangular de dimensiones x, y, z como se muestra en la figura. El volumen del contenedor deberá ser de 0.08 $m^3$. Por requerimientos, la altura debe estar en el rango 0.6-0.8 m, y los lados de la base deben medir al menos 0.1 m. Luego, la idea es diseñar el contenedor de tal forma que se utilice la menor cantidad de material posible. Nota: El contenedor está abierto en la parte superior.
La cantidad de material utilizada para fabricar el contenedor está directamente relacionada con el área del prisma rectangular, donde esta corresponde a la suma de las áreas para cada una de las caras, luego, basándonos en el esquema de la figura anterior, se puede expresar el área en función de sus dimensiones como sigue:
Un valor óptimo no restringido puede calcularse mediante herramientas elementales de cálculo variacional. Para obtener un punto crítico se resuelve el sistema de ecuaciones resultante de igualar a cero el gradiente de la función, es decir:
$$ \left[ \vec{\nabla} f \right] = [0] $$
Esto lo podemos calcular utilizando SymPy. Importamos la librería y las funciones hessian y zeros del módulo matrices:
In [1]:
from__future__importdivisionimportsympyassymfromsympy.matricesimporthessian,zerossym.init_printing(use_latex="mathjax")defgradient(f,varls):""" Calcula el gradiente de una función f(x1,x2,...)"""n=len(varls)G=zeros(n,1)foriinrange(n):G[i]=f.diff(varls[i])returnG
Definimos las variables simbólicas a utilizar y la función $A(x_1,x_2)$
Se obtienen dos soluciones complejas y una real, además, la solución real presenta dos valores iguales.
Hasta ahora sabemos que la solución obtenida es un punto crítico, pero no podemos asegurar si es un máximo, un mínimo o un punto de silla. Luego, para comprobar si el punto calculado es un mínimo se puede utilizar el siguiente teorema:
Teorema 1. Condición necesaria: si $f(x)$ tiene un mínimo local en $x^*$ entonces:
es positiva definida o semidefinida en el punto $x^*$.
Condición suficiente de segundo orden: si la matriz $H(x^*)$ es positiva definida en el punto estacionario $x^*$,
entonces $x^*$ es un mínimo local para la función $f(x)$.
Una matriz es positiva definida si sus eigenvalores son estrictamente positivos, es decir: $\lambda_i > 0$
De acuerdo al teorema 1, para que el punto calculado sea un mínimo, los eigenvalores de la matriz Hessiana de $A(x_1, x_2)$ evaluada en el punto crítico deben ser positivos.
Calculando la matriz Hessiana:
In [5]:
H=hessian(A,(x1,x2))# evaluando en el punto calculado_x1,_x2=sol[0][0],sol[0][1]H=H.subs({x1:_x1,x2:_x2,V:0.08})H
Dado que tanto $\lambda_1 = 1$ como $\lambda_2 = 3$ son positivos, entonces el punto calculado es un mínimo global no restringido.
Ahora, si calculamos el valor de la altura $x_3$:
In [59]:
_x3=0.08/(_x1*_x2)_x3
Out[59]:
$$0.271441761659491$$
Vemos que no cumple con la restricción de altura dada. En lo subsiguiente se abordará el cómo utilizar otros métodos para resolver problemas de optimización con restricciones.
La optimización con restricciones implica tomar en cuenta ecuaciones que definen regiones factibles. Uno de los métodos más simples para resolver problemas con restricciones es el método gráfico.
Resolver un problema de optimización por el método gráfico implica trazar las gráficas de contorno de la función objetivo, así como las regiones definidas por las restricciones, y luego mediante inspección ubicar el punto que optimice la función objetivo. Claro está que es un método que puede resultar poco preciso, pero normalmente sirve para dar una aproximación aceptable y que pueda utilizarse como punto de entrada para algoritmos numéricos como los que se verán en la siguiente sección.
Lo primero que haremos es importar las librerías a utilizar: NumPy y Matplotlib.
Para trazar la gráfica de contorno de $A(x_1,x_2)$ utilizamos la función contour:
In [57]:
plt.contour(x1,x2,f,cmap="viridis")
Out[57]:
<matplotlib.contour.QuadContourSet at 0xbb675f0>
Vemos que la gráfica obtenida no parece muy adecuada, esto debido a que los niveles utilizados por defecto no se ajustan a la función en cuestión. Si evaluamos $A(x_1,x_2)$ en el punto óptimo no restringido de la sección anterior se tiene:
In [63]:
A.subs({"x_1":_x1,"x_2":_x2,"V":0.08})
Out[63]:
$$0.884167559673693$$
Luego, se pueden utilizar niveles personalizados para la función contour, partiendo desde el valor mínimo anterior:
De la gráfica anterior, la región factible corresponde a la región ubicada entre las líneas rojas y azules correspondientes a las ecuaciones de restricción para la altura $g_1$ y $g_2$. Esto se puede hacer más evidente se utilizamos la función contourf.
El análisis estructural es uno de los aspectos elementales para aquellos
que nos dedicamos al diseño mecánico o cuestiones similares. En los cursos
universitarios de resistencia de materiales se enseñan algunos métodos
analíticos que permiten obtener soluciones rápidas para componentes mecánicos
simples. No obstante, cuando las geometrías se complican se hace necesario
utilizar el enfoque numérico e implementar una metodología de solución utilizando
el método de los elementos finitos, el cual proporciona una solución aproximada
que será adecuada en medida de ciertos criterios, tales como el tamaño y tipo de
elementos, la física del problema, entre otros.
El propósito del presente minicurso es introducir al lector en el uso de las
herramientas numéricas que proporciona Python para la solución de problemas de
análisis estructural utilizando el método de los elementos finitos.
El método de los elementos finitos consiste
en la discretización de un continuo en pequeños elementos, con la finalidad de
establecer un sistema de ecuaciones que describa de manera aproximada el comportamiento
individual y global del sistema, pasando por la inclusión de las condiciones de frontera y todas
las consideraciones físicas que deriven en la simplificación del problema.
En análisis numérico estructural el método de los desplazamientos o de la rigidez, asume
que los desplazamientos nodales son las variables desconocidas y comúnmente se debe resolver
una ecuación algebraica del tipo:
$$ K U = F $$
Donde $F$ es el vector de fuerzas nodales, $K$ la matriz global de rigidez y $U$ el vector
de desplazamientos nodales.
Dado que normalmente los desplazamientos son las incógnitas, se tiene que:
$$ U = K^{-1} F $$
En el caso de un análisis estático lineal esta ecuación se resuelve como se muestra: calculando la inversa de la matriz rigidez y multiplicando por el vector de fuerzas nodales, para el caso de un análisis no lineal se utilizan métodos iterativos.
La matriz global $K$ se obtiene de ensamblar todas las matrices de rigidez por elemento acorde a la numeración o posición de
sus nodos.
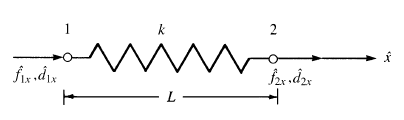
La obtención de la matriz de rigidez puede consultarla en la mayoría de los libros introductorios de elementos finitos, por ejemplo en [1]. En lo anterior $k_e$ es la rigidez característica del resorte.
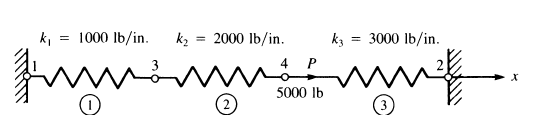
Para ejemplificar cómo funciona el método de los elementos finitos en elementos de este tipo vamos a resolver el siguiente ejemplo.
Primero, las matrices de rigidez por elemento vienen dadas por:
La matriz global se obtiene ensamblando las matrices elementales utilizando el principio de superposición, es decir, asumiendo que los efectos individuales de cada elemento a la matriz global pueden adicionarse de manera independiente. Para esto se debe expandir la matriz de rigidez elemental y rellenar sólo las posiciones correspondientes a los nodos que componen el elemento.
Por ejemplo, el elemento 1 está conformado por los nodos 1 y 3, entonces:
importnumpyasnpimportnumpy.linalgasla# Datos inicialesk1=1000.0k2=2000.0k3=3000.0P=5000.0# Matrices por elementoK1=np.array([[k1,-k1],[-k1,k1]])K2=np.array([[k2,-k2],[-k2,k2]])K3=np.array([[k3,-k3],[-k3,k3]])# Matriz global K=np.array([[K1[0,0],0,K1[0,1],0],[0,K3[0,0],0,K3[0,1]],[K1[1,0],0,K1[1,1]+K2[0,0],K2[0,1]],[0,K3[1,0],K2[1,0],K2[1,1]+K3[1,1]]])F=np.array([0,0,0,P])# Condiciones de frontera# Nodos 1 y 2 conocidos -> UX = 0KS=K[2:,2:]FS=F[2:]# ResolviendoUSOL=la.solve(KS,FS)# Vector de desplazamientosUSOL=np.concatenate(([0,0],USOL))# Obteniendo las fuerzas nodalesNF=np.dot(K,USOL)# Presentando los resultadosfornodoinrange(4):print("%g UX = %-8.4f FX = %-8.4f"%(nodo+1,USOL[nodo],NF[nodo]))
1 UX = 0.0000 FX = -909.0909
2 UX = 0.0000 FX = -4090.9091
3 UX = 0.9091 FX = 0.0000
4 UX = 1.3636 FX = 5000.0000
Utilizando NuSA: una librería para análisis estructural¶
NuSA es una librería Python para el análisis estructural, que facilita el planteamiento y la solución de este tipo de análisis mediante una colección de clases que reciben como dato de entrada las características elementales de un modelo: coordenadas modales, propiedades del material, condiciones de frontera, etc., y retorna valores de salida básicos como desplazamientos y fuerzas.
Para testear las capacidades de NuSA vamos a resolver el ejemplo del elemento resorte. Lo primero es importar las clases que usaremos: Node, Spring y SpringModel.
En este caso no es necesario especificar las coordenadas nodales dado que un elemento resorte sólo necesita la rigidez para la formulación, así que se pueden dejar ambos nodos con coordenadas (0,0).
Enseguida se define un elemento de tipo SpringElement, cuyos datos de entrada son una tupla con los nodos que le conforman y la rigidez del elemento.
Luego, establecemos las condiciones de frontera y la carga externa aplicada. Finalmente utilizamos el método solve e imprimimos los resultados obtenidos.
In [41]:
m1.add_constraint(n1,ux=0)m1.add_constraint(n2,ux=0)m1.add_force(n4,(5000,))m1.solve()fornodoinm1.get_nodes():print("%s UX = %-8.4f FX = %-8.4f"%(nodo.label,nodo.ux,nodo.fx))
0 UX = 0.0000 FX = -909.0909
1 UX = 0.0000 FX = -4090.9091
2 UX = 0.9091 FX = 0.0000
3 UX = 1.3636 FX = 5000.0000
[1] Logan, D. L. (1986). A first course in the finite element method. Boston: PWS Engineering.
[2] Zienkiewicz, O. C., Taylor, R. L., Zhu, J. Z., Zienkiewicz, O. C., & Zienkiewicz, O. C. (2005). The finite element method: Its basis and fundamentals. Oxford: Elsevier Butterworth-Heinemann.
Las integrales son unos de los conceptos básicos en la formación matemática de un ingeniero, es en términos básicos la
operación inversa de la derivación. Pero, además del concepto puramente matemático, las integrales tienen múltiples
interpretaciones geométricas y físicas.
En un curso ordinario de cálculo se nos enseñan métodos para resolver de forma analítica funciones que sean integrables.
Por ejemplo todos sabemos que la integral de una función constante será:
$$ \int a\,dx = ax + C $$
Y lo sabemos porque nos hemos aprendido reglas básicas de integración y por supuesto a indentificar el tipo
de función. Actualmente existen paquetes de álgebra simbólica que son capaces de realizar esta tarea: identificar
el caso que se tiene y aplicar métodos computacionales, hasta cierto grado complejos, para determinar la solución.
Y claro, SymPy es uno de esos sistemas de álgebra computacional (CAS), en el que solo necesitamos escribir
nuestra función a integrar, utilizar por ahí alguna rutina y obtener un resultado rápidamente. Pero claro,
para ello debemos aprender mínimamente la sintaxis y eso es justo lo que veremos enseguida.
Vamos a ver cómo resolver integrales simples indefinidas, si, de esas que vemos en un primer curso. Para resolverlas
tendremos que utilizar la función integrate. Por ejemplo se tiene la siguiente función $f(x)=x^2-3x+2 $.
Como primer paso debemos importar lo que necesitaremos del paquete SymPy:
Del módulo abc importamos la variable simbólica x e integrate para resolver nuestra integral. Ahora, podemos
guardar la función a integrar en una variable o bien pasarla directamente como argumento:
In [2]:
f=x**2-3*x+2integrate(f)
Out[2]:
$$\frac{x^{3}}{3} - \frac{3 x^{2}}{2} + 2 x$$
En este caso no hemos tenido incovenientes, porque en la expresión a integrar sólo existe una variable simbólica, pero
si la expresión tuviese más de una, habría que especificar de manera explícita la variable respecto a la cual se integra, de lo contrario Python nos mostrará un error:
---------------------------------------------------------------------------ValueError Traceback (most recent call last)
<ipython-input-3-476839d3c49d> in <module>() 1from sympy.abc import a,b,c
2 f = a*x**2+b*x+c
----> 3integrate(f)~\Anaconda3\lib\site-packages\sympy\integrals\integrals.py in integrate(*args, **kwargs) 1289 risch = kwargs.pop('risch',None) 1290 manual = kwargs.pop('manual',None)-> 1291integral = Integral(*args,**kwargs) 1292 1293if isinstance(integral, Integral):~\Anaconda3\lib\site-packages\sympy\integrals\integrals.py in __new__(cls, function, *symbols, **assumptions) 73return function._eval_Integral(*symbols,**assumptions) 74---> 75obj = AddWithLimits.__new__(cls, function,*symbols,**assumptions) 76return obj
77~\Anaconda3\lib\site-packages\sympy\concrete\expr_with_limits.py in __new__(cls, function, *symbols, **assumptions) 375" more than one free symbol, an integration variable should" 376" be supplied explicitly e.g., integrate(f(x, y), x)"--> 377 % function)
378 limits, orientation =[Tuple(s)for s in free],1 379ValueError: specify dummy variables for a*x**2 + b*x + c. If the integrand contains more than one free symbol, an integration variable should be supplied explicitly e.g., integrate(f(x, y), x)
Pues eso, si intentamos integrar la función $f(x)=ax^2+bx+c$ sin especificar la variable de integración, Python nos mandará un error que es bastante sugerente al respecto. Así, lo correcto sería:
Una integral definida usualmente se utiliza para calcular el área bajo la curva de una función en un intervalo finito. En SymPy, para calcular una integral definida se utiliza la función integrate, considerando el hecho que deben adicionarse los límites de evaluación mediante la sintaxis:
integrate(fun, (var, a, b))
Donde fun es la función, var la variable respecto a la cual se integra, a el límite inferior y b el límite superior.
Para ejemplificar vamos a resolver la siguiente integral definida:
Ahora vamos a resolver integrales dobles (la sintaxis/metodología de resolución que se revisará aplica para cualquier integral múltiple). Por ejemplo vamos a resolver la integral dada por:
$$ \int_a^b \int_c^d \, dy \, dx $$
Recuerde que este tipo de integrales múltiples se resuelven de forma iterada, yendo de dentro hacia afuera, es decir, para la integral anterior se procedería:
$$ I_1 = \int_c^d \, dy \qquad \rightarrow \qquad I = \int_a^b \, I_1 \, dx $$
En esta breve entrada vamos a hablar de cómo utilizar la función ìmg2py de wxPython, para generar códigos a partir de imágenes, y posteriormente poder utilizarlas en conjunto conPyEmbeddedImage.
Lo primero que debemos hacer es importar la función del módulo wx.tools.img2py:
from wx.tools.img2py import img2py
Y posteriormente sólo llamaremos a la función pasando como argumentos el archivo de la imagen y el archivo Python de salida, por ejemplo:
img2py("icono.png", "icono.py")
Con lo anterior se obtendrá un archivo Python icono.py que contiene algo parecido a lo siguiente:
#---------------------------------------------------------------------- # This file was generated by C:\Users\User\Desktop\LABPro\_blogs_\Posts\test_app.py # from wx.lib.embeddedimage import PyEmbeddedImage
¿Y si necesito embeber varias imágenes en un mismo archivo Python?
Si, es bastante probable que necesite esto, hacer una colección de imagenes embebidas en un mismo archivo Python, la cuestión es muy parecida, sólo tenemos que agregar el keyword argumentappend a la función img2py para evitar que borre lo que se ha colocado anteriormente, un pequeño ejemplo:
import glob from wx.tools.img2py import img2py
if__name__=='__main__': for img in glob.glob("img/*.png"): img2py(img,"iconos.py", append=True)
Lo anterior incrusta el código correspondiente a todas las imágenes PNG contenidas en la carpeta img/.